Model benchmarks
Every model runs fully on-device. Pick the one that fits your hardware and accuracy needs.
At a glance
Ratings computed from benchmark data, scaled 1 to 10. Accuracy is based on Word Error Rate (WER) and does not include punctuation yet.
| Name | Lang | Translate | Speed | Accuracy |
|---|---|---|---|---|
| Large V3 Turbo q5_0 | all | ✘ | 7 | 9 |
| Large V3 q5_0 | all | ✔ | 6 | 9 |
| Parakeet TDT v3 | 25 | ✘ | 10 | 9 |
| Small q5_1 | all | ✔ | 9 | 7 |
Which model should you pick?
Best accuracy (multilingual)
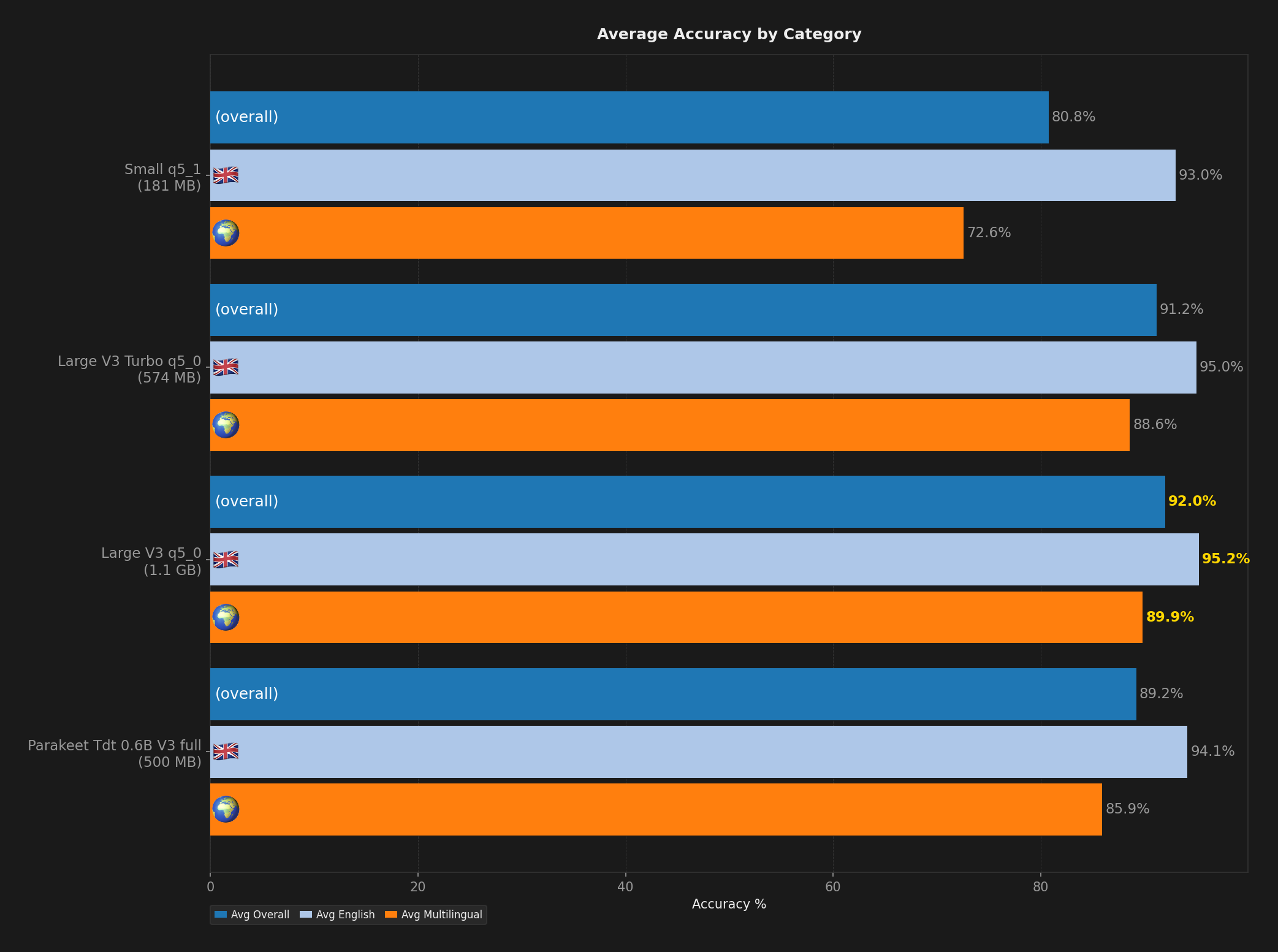
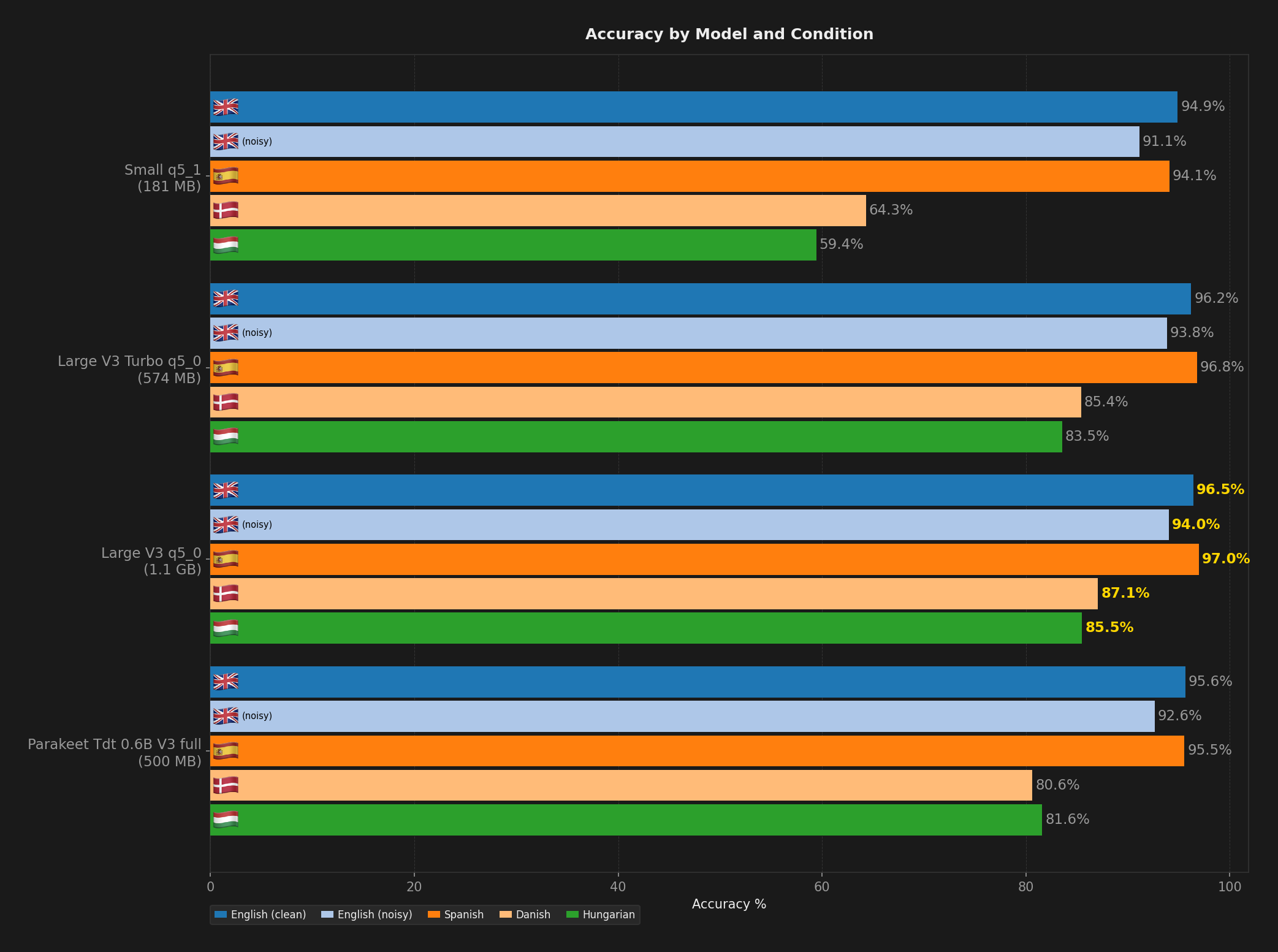
Large V3 q5_0 takes the crown here. It scored 96.3% accuracy on clean English and held strong across Spanish, Danish, and Hungarian. The full Large V3 gets the exact same accuracy, but eats nearly 4 GB of RAM. The q5_0 quantized version cuts that in half to about 2 GB while keeping every bit of precision. At 1.1 GB on disk, it is the go-to if you care about getting words right across languages.
Best accuracy (English only)
Medium q5_0 en hits 95.7% on clean English at just 514 MB on disk and about 1.1 GB of RAM. If that still feels heavy, Small q5_1 en is worth a look. It scores 95.4% at only 181 MB on disk and 475 MB of RAM. Nearly the same accuracy at a third of the size.
Fastest
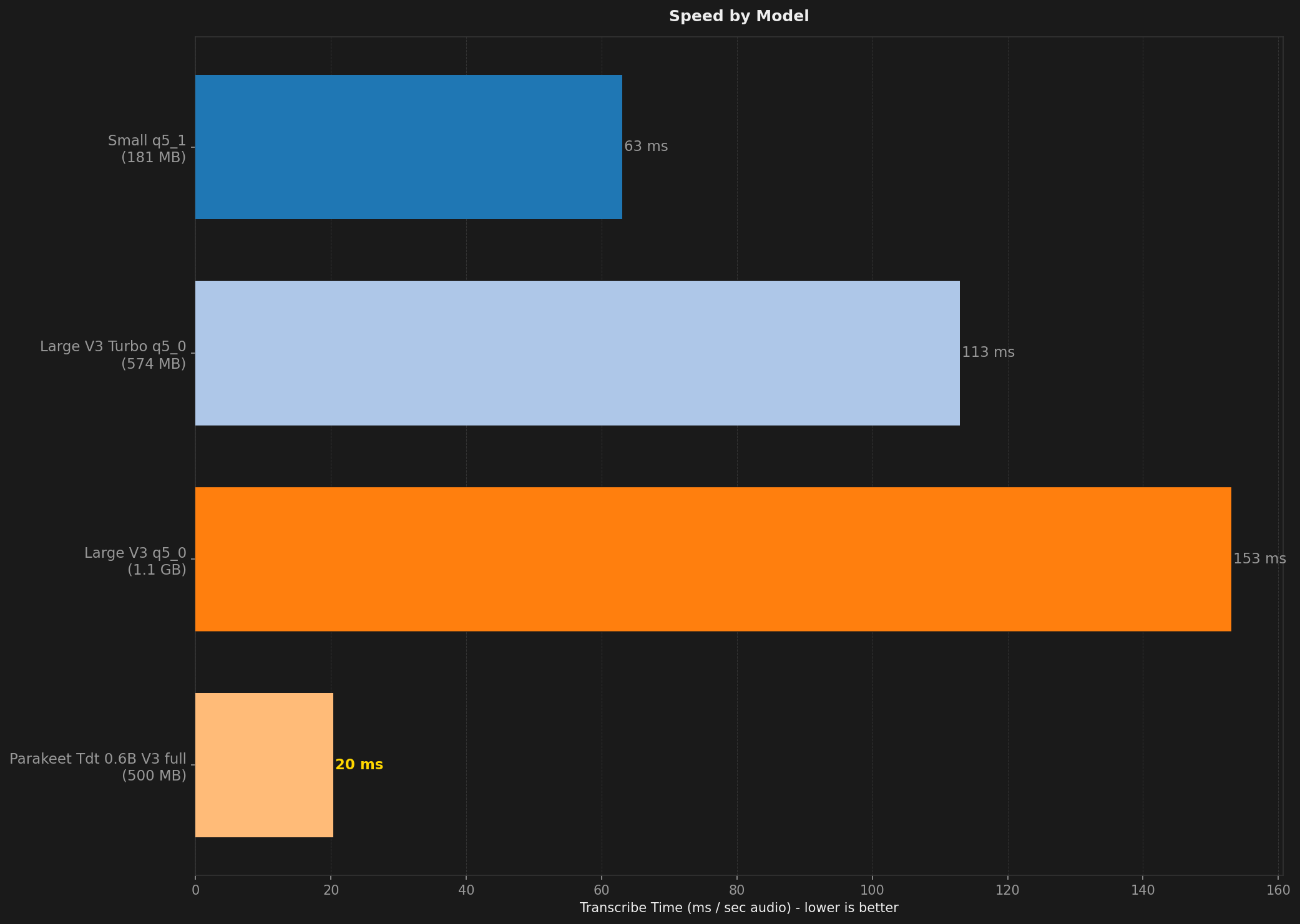
Parakeet TDT v3 is in another league. It runs 3 to 10 times faster than any Whisper model, uses just 80 MB of RAM, and still manages 95.7% accuracy on clean English. If raw throughput is what you need, nothing else comes close.
Daily driver
This one depends on your workflow. If you mostly dictate in English in a quiet environment, Parakeet TDT v3 is hard to beat. It is faster, lighter, and more accurate on clean audio than the Turbo models.
But if you switch between languages or deal with noisy audio, Large V3 Turbo q5_0 is the safer bet. It scores 95.1% on clean English, 94.6% on noisy, and 96.8% on Spanish, all at around 800 MB of RAM. It covers more ground.
Translation
Large V3 q5_0 wins again. It is the same model as the accuracy pick above and it also supports translation. Worth noting: the Turbo models (Turbo, Turbo q5_0, Turbo q8_0) do not support translation, so if you need that feature, Large V3 q5_0 is your only high-accuracy option.
Lightweight
Small q5_1 gives you the best accuracy-to-size ratio. It supports all languages, has translation, and scores 94.5% on clean English. All that at 181 MB on disk and 475 MB of RAM. If your machine is tight on resources, this is the one.
Detailed results
| Model | Samples | Disk | RAM | Speed | Avg overall | Avg EN | Avg multi | EN | EN noisy | ES | DA | HU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Large V3 q5_0 | 200 | 1.1 GB | 2.0 GB | 147 ms | 92.0% | 95.2% | 89.9% | 96.5% | 94.0% | 97.0% | 87.1% | 85.5% |
| Large V3 Turbo q5_0 | 200 | 574 MB | 801 MB | 105 ms | 91.2% | 95.0% | 88.6% | 96.2% | 93.8% | 96.8% | 85.4% | 83.5% |
| Parakeet TDT v3 | 200 | 500 MB | 80 MB | 19 ms | 89.2% | 94.1% | 85.9% | 95.6% | 92.6% | 95.5% | 80.6% | 81.6% |
| Small q5_1 | 200 | 181 MB | 477 MB | 58 ms | 80.8% | 93.0% | 72.6% | 94.9% | 91.1% | 94.1% | 64.3% | 59.4% |
Methodology
Test setup
Each model transcribed 200 utterances per dataset after 3 warmup passes. Datasets include LibriSpeech (clean and noisy English) and FLEURS (Spanish, Danish, Hungarian).
What the columns mean
Disk is the download size. Memory (avg) is peak resident set size averaged across all conditions. Speed is time to transcribe one second of audio, so lower is better. Accuracy columns show approximate word accuracy per language condition.
How accuracy is measured
Accuracy is based on Word Error Rate (WER), which compares transcribed words against a reference transcript. WER does not account for punctuation, capitalization, or formatting. A model can score high on WER and still miss commas, periods, and question marks entirely.
We are actively working on adding Character Error Rate (CER) benchmarks, which measure accuracy at the character level and will capture punctuation quality. Once those results are in, the rankings here may shift for models that handle punctuation better than others.
Hardware
All runs executed on Apple M4 Max / 36 GB / macOS 26.4.1 with no other significant workloads. Results on different hardware will vary, but relative model ranking is stable.
Visual comparison
About Codictate
Codictate runs speech-to-text entirely on your device. No internet, no account, no cloud processing. Press a shortcut and your words appear wherever you type: IDE, browser, chat, email, or terminal.
It supports macOS (Apple Silicon) and Windows, ships with the Whisper Large Turbo model by default, and lets you swap to smaller or larger models depending on your accuracy and memory requirements.