Benchmarks
Every benchmark run we have conducted, comparing speech-to-text models by accuracy, speed, and resource usage.
All models compared
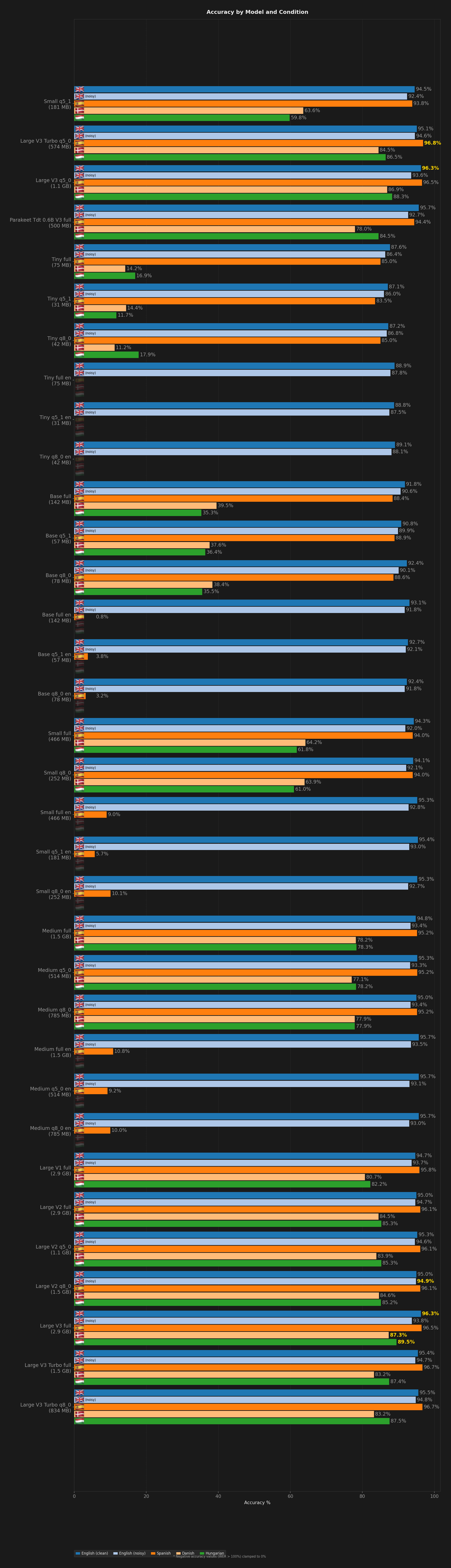
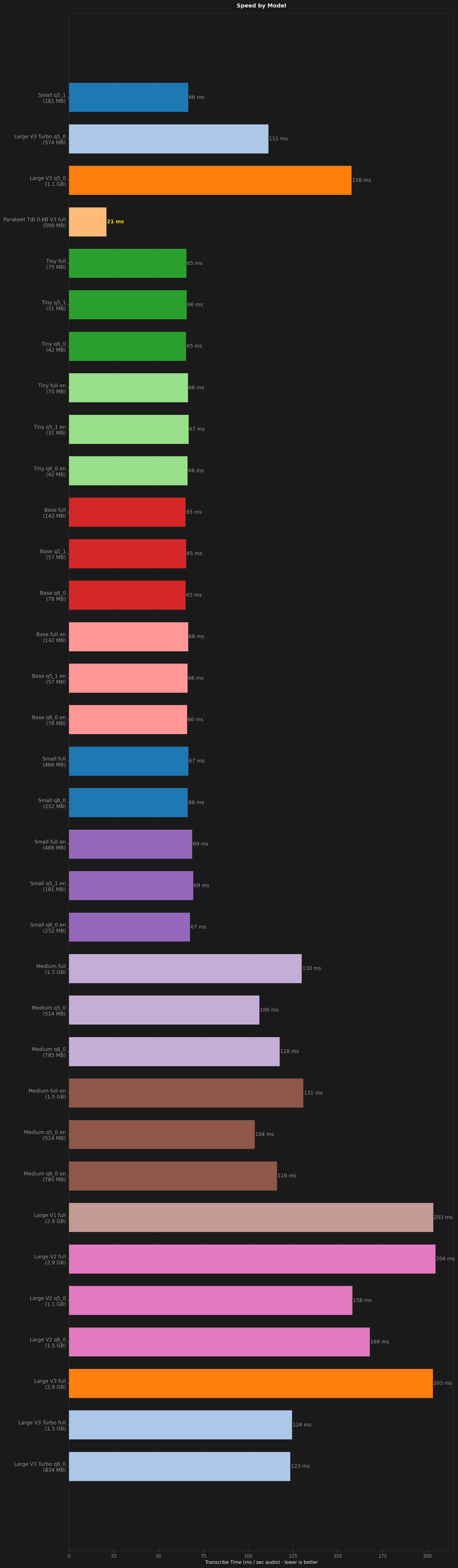
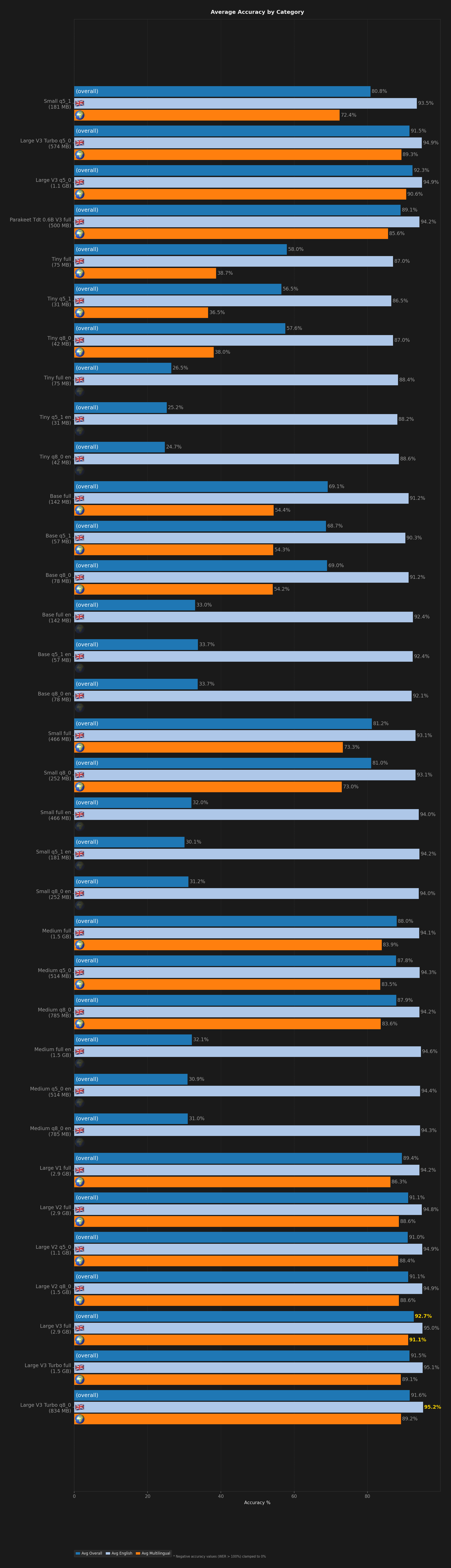
All benchmark runs
- May 9, 202634 models50 samples
Initial model benchmarks to see if there are some models that we should leave out for a more extensive benchmark that will include way more samples. This does not include the Tiny/Base models which has been tested initially already
- May 9, 202612 models50 samples
Triage of Tiny and Base model families (all quantization and language variants) to evaluate whether these smaller models are worth further benchmarking.
- FeaturedMay 8, 20264 models200 samples
Comparison of Codictate's curated speech models (Small q5_1, Large V3 Turbo q5_0, Large V3 q5_0, Parakeet) to determine the best-performing default model.