
Most speech-to-text benchmarks test models in isolation. Clean environment, research pipeline, controlled inputs. That is useful for comparing architectures, but it does not tell you how a model actually performs when it runs through a real product on a real Mac.
So we ran the benchmarks ourselves, through Codictate's own pipeline.
What we tested and how
4 models: Whisper Small, Whisper Large v3 Turbo, Whisper Large v3, and Parakeet TDT 0.6B v3.
5 conditions: English (clean audio), English (noisy audio), Spanish, Danish, and Hungarian.
200 samples per condition, per model. That is roughly 4,000 individual transcriptions. Each model got 3 warmup runs before we started measuring. All text was normalized using whisper-basic normalization so the comparison would be fair across models.
Everything ran on an Apple M4 Max with 36 GB of RAM, macOS 26.4.1. No cloud. No GPU server. The same kind of machine you would actually use Codictate on.
We measured three things: accuracy (word error rate), speed (how many milliseconds of processing per second of audio), and memory (peak RAM usage).
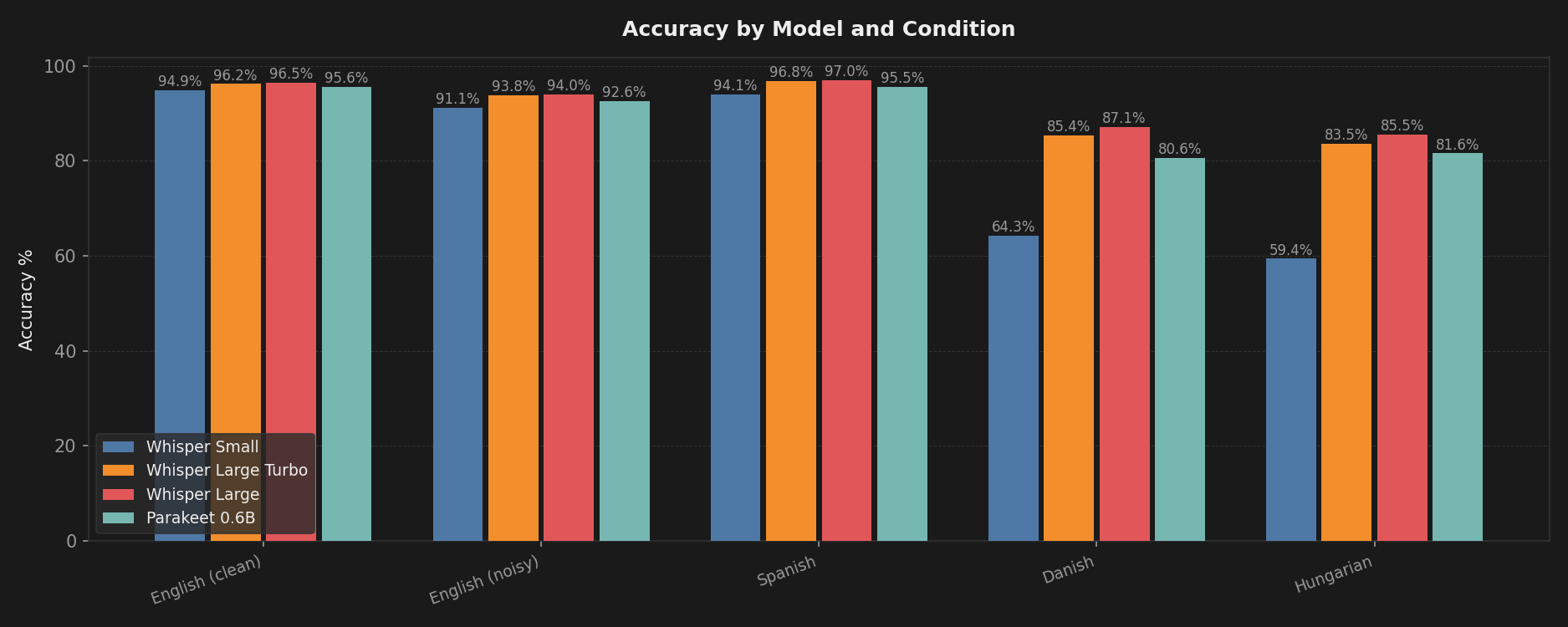
Accuracy: Whisper Large wins, but not by as much as you would think
| English (clean) | English (noisy) | Spanish | Danish | Hungarian | |
|---|---|---|---|---|---|
| Whisper Small | 94.9% | 91.1% | 94.1% | 64.3% | 59.4% |
| Whisper Large Turbo | 96.2% | 93.8% | 96.8% | 85.4% | 83.5% |
| Whisper Large | 96.5% | 94.0% | 97.0% | 87.1% | 85.5% |
| Parakeet 0.6B | 95.6% | 92.6% | 95.5% | 80.6% | 81.6% |
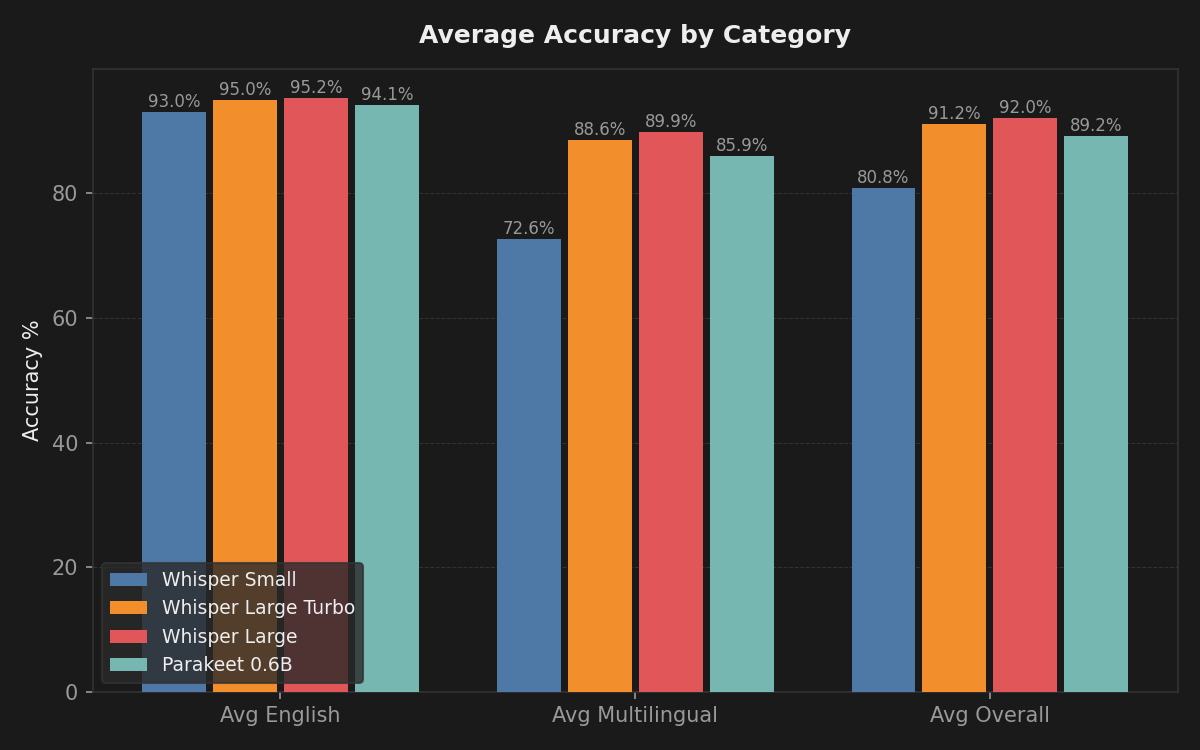
For English and Spanish, all four models are surprisingly close. Parakeet hits 95.6% on clean English, only one percentage point behind Whisper Large.
The gap widens on languages like Danish and Hungarian, where Whisper Large pulls ahead with 87.1% and 85.5% respectively. Whisper Small falls off a cliff on those same languages (64.3% Danish, 59.4% Hungarian), which makes sense given the model size.
Parakeet lands in the middle for multilingual work. Not the best, not the worst.
Speed: Parakeet is absurdly fast
This is where it gets interesting.
| Model | Processing time per second of audio |
|---|---|
| Parakeet 0.6B | 19 ms |
| Whisper Small | 58 ms |
| Whisper Large Turbo | 105 ms |
| Whisper Large | 147 ms |
Parakeet processes one second of audio in 19 milliseconds. That is nearly 8x faster than Whisper Large and 3x faster than Whisper Small.
This is why Parakeet powers stream mode. When you are transcribing in real time as someone talks, you need a model that can keep up without lag. At 19ms per second of audio, Parakeet has headroom to spare.
Whisper Large takes 147ms, which is still well under real-time (it would need to exceed 1,000ms to fall behind). But the extra margin matters for battery life and keeping your Mac responsive while you dictate.
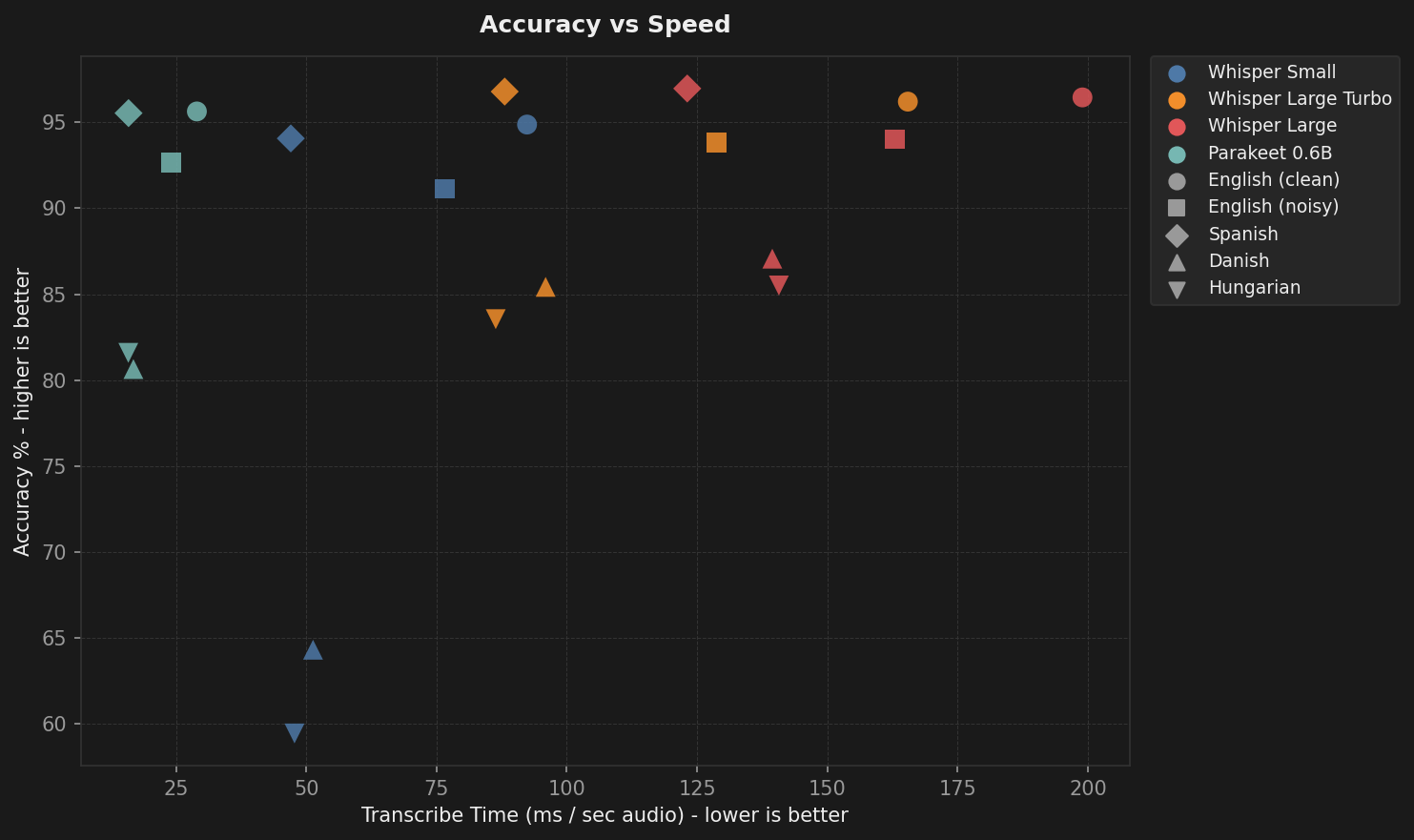
Memory: Parakeet uses 25x less RAM than Whisper Large
| Model | Peak RAM (average) |
|---|---|
| Parakeet 0.6B | 80 MB |
| Whisper Small | 476 MB |
| Whisper Large Turbo | 801 MB |
| Whisper Large | 1,987 MB |
This was the number that surprised me the most. Parakeet runs at 80 MB. Whisper Large sits at nearly 2 GB.
If you are on a MacBook Air with 8 GB of RAM, that difference matters. Whisper Large eats a quarter of your total memory just to transcribe. Parakeet barely registers.
The vocabulary trade-off nobody talks about
There is one thing these accuracy numbers do not capture: vocabulary.
Whisper was trained on a massive amount of internet audio. That means it already knows words like "Cursor," "Wispr Flow," "Vercel," "Kubernetes," and thousands of other product names and technical terms. When you say "open Cursor," Whisper writes "Cursor." Parakeet might write "cursor" or something close, which is where Codictate's dictionary steps in to correct it.
This matters if you spend your day talking about specific tools and frameworks. Whisper has a head start on that kind of vocabulary. Parakeet can learn it through the dictionary, but it takes some teaching.
So which model should you pick?
It depends on what you care about.
If you dictate mostly in English or Spanish, pick Parakeet. The accuracy difference compared to Whisper Large is small (around 1 percentage point on clean audio), but Parakeet is 8x faster and uses 25x less memory. It also powers stream mode, which Whisper cannot do. If you need proper nouns and product names, add them to the dictionary and Parakeet will handle them just fine.
Whisper Large Turbo is the model I would point most people to if they want Whisper. It scores within 1-2 percentage points of Whisper Large on every condition we tested, but it uses 801 MB of RAM instead of nearly 2 GB. That is less than half the memory cost for almost the same accuracy. On Danish it hits 85.4% compared to Whisper Large's 87.1%. On Spanish it is 96.8% versus 97.0%. Those gaps are tiny. Unless you are chasing the absolute last fraction of accuracy, Turbo gives you the Whisper experience without punishing your machine.
Whisper Large is hard to justify for most users. Yes, it is the most accurate model in the lineup. But it sits at nearly 2 GB of RAM. On a MacBook with 8 GB, that is a quarter of your total memory just for transcription. And the accuracy gain over Turbo is marginal, usually around 1-2 percentage points. If you dictate in a language where every percentage point counts and you have the RAM to spare, it is there. For everyone else, Turbo gets you almost the same result at half the cost.
If you need translation, only Whisper Small and Whisper Large support it. That is a hard constraint, not a preference.
Whisper Small is hard to recommend unless you are very tight on disk space (181 MB vs 500+ MB for the others). Its English accuracy is acceptable but its multilingual performance drops significantly.
What I personally use
I run Whisper Large Turbo for my daily dictation. The accuracy is close to Whisper Large, the RAM cost is reasonable, and there is one thing the numbers above do not show: Whisper handles the messy parts of real speech better. It cleans up stutters, removes filler words like "uh" and "err," and produces properly punctuated text. Parakeet is faster, but its punctuation and formatting are noticeably rougher.
When I dictate a paragraph and Turbo gives me clean, readable text on the first pass, that matters more to me than saving a few milliseconds.
Why we did this ourselves
Published benchmarks test models in isolation. Codictate runs these models through Core ML on Apple Silicon, with specific quantization settings, audio preprocessing, and text normalization. The numbers on a model card do not always match what you get in a real product.
The full benchmark results are on the about page, including interactive charts for accuracy and speed.
If you have not tried Codictate yet, grab it from the download button in the navbar. If you want the quick setup guide, read How To Use Dictation on Your Mac.