
After benchmarking our main models across 4,000 transcriptions, the next question was obvious: what about Whisper's smallest models? Before committing to a full benchmark on Tiny and Base, we ran a 50-sample triage. Just enough data to see if these models are worth the full treatment.
The short answer: Tiny is not competitive. Base is surprisingly decent for English, but falls apart on other languages.
The results at a glance
| Model family | Avg. English accuracy | Avg. multilingual accuracy | RAM range |
|---|---|---|---|
| Tiny | 86.6 - 87.0% | 36.5 - 38.7% | 153 - 220 MB |
| Tiny.en | 88.2 - 88.6% | English only | 156 - 222 MB |
| Base | 90.4 - 91.3% | 54.2 - 54.4% | 217 - 332 MB |
| Base.en | 92.1 - 92.5% | English only | 216 - 333 MB |
| Small (reference) | 93.0% | 72.6% | 476 MB |
For context, Small scored 93.0% average English accuracy in our previous benchmark. Base.en comes within one percentage point. Tiny sits 5-6 points behind.
The multilingual gap is bigger. Small averaged 72.6% across Spanish, Danish, and Hungarian. Base managed 54.4%. Tiny landed below 39%. Figure 1 shows every model variant side by side across all five test conditions.
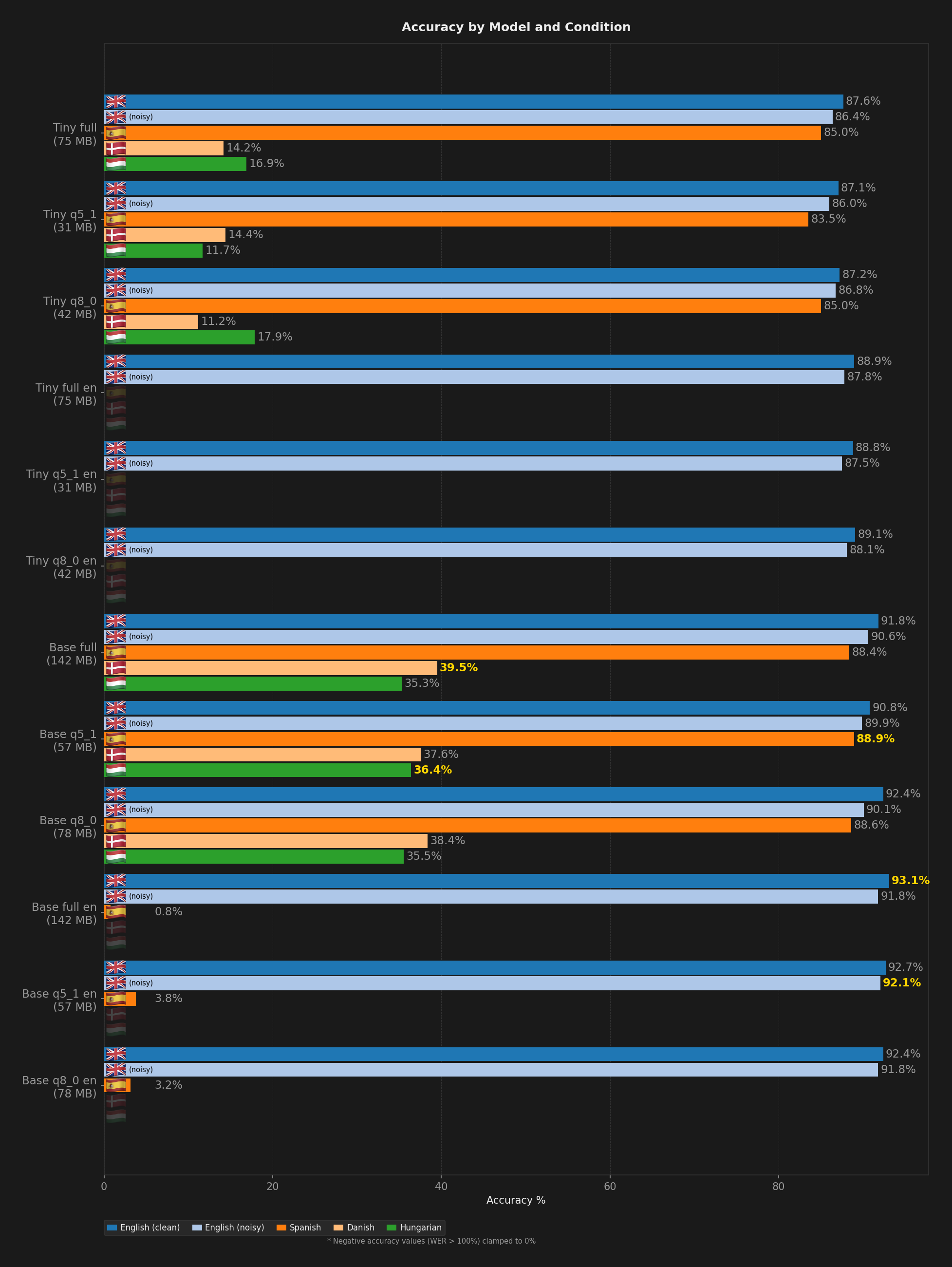 Figure 1: Accuracy by model and condition.
Figure 1: Accuracy by model and condition.
What we tested and how
12 model variants: Tiny, Tiny.en, Base, and Base.en, each in three versions: full precision, q8_0 quantized, and q5_1 quantized.
Quantization is a way to shrink a model by reducing the precision of its numbers. The full-precision model keeps all its original detail. q8_0 rounds those numbers to 8-bit integers, which cuts the file size roughly in half while keeping most of the accuracy. q5_1 compresses further to around 5 bits, saving more space and memory at the cost of slightly more rounding error.
5 conditions: English clean audio and English noisy audio from LibriSpeech, plus Spanish, Danish, and Hungarian from FLEURS.
50 samples per condition, per model. Each model got 3 warmup runs before measurement. All text was normalized using whisper-basic normalization. Everything ran on an Apple M4 Max with 36 GB of RAM, macOS 26.4.1. Same hardware and pipeline as our previous benchmark.
English accuracy: Base.en is closer to Small than expected
| Model | English (clean) | English (noisy) | Avg. English |
|---|---|---|---|
| tiny | 87.6% | 86.4% | 87.0% |
| tiny-q5_1 | 87.1% | 86.0% | 86.6% |
| tiny-q8_0 | 87.2% | 86.8% | 87.0% |
| tiny.en | 88.9% | 87.8% | 88.4% |
| tiny.en-q5_1 | 88.8% | 87.5% | 88.2% |
| tiny.en-q8_0 | 89.1% | 88.1% | 88.6% |
| base | 91.8% | 90.6% | 91.2% |
| base-q5_1 | 90.8% | 89.9% | 90.4% |
| base-q8_0 | 92.4% | 90.1% | 91.3% |
| base.en | 93.1% | 91.8% | 92.5% |
| base.en-q5_1 | 92.7% | 92.1% | 92.4% |
| base.en-q8_0 | 92.4% | 91.8% | 92.1% |
| Small (reference) | 94.9% | 91.1% | 93.0% |
Base.en hits 93.1% on clean English. That is only 1.8 percentage points behind Small. On noisy audio, base.en-q5_1 actually edges ahead of Small: 92.1% vs 91.1%. I did not expect that. With only 50 samples the margin of error is wider than our full benchmark, so that result might not hold with more data. But it is a strong signal that Base.en deserves a closer look.
The .en variants consistently outperform their multilingual counterparts by 1-2 percentage points on English. They were trained exclusively on English data, so that makes sense.
Quantization barely hurts accuracy. Base.en vs base.en-q5_1 is 93.1% vs 92.7%, a difference of 0.4 points. For the memory savings (333 MB down to 216 MB), that is a good trade.
Tiny tops out at 89.1% on clean English with tiny.en-q8_0. That is 4 points behind Base.en and nearly 6 behind Small. The gap is too wide. Figure 2 breaks this down into average English and average multilingual accuracy per model.
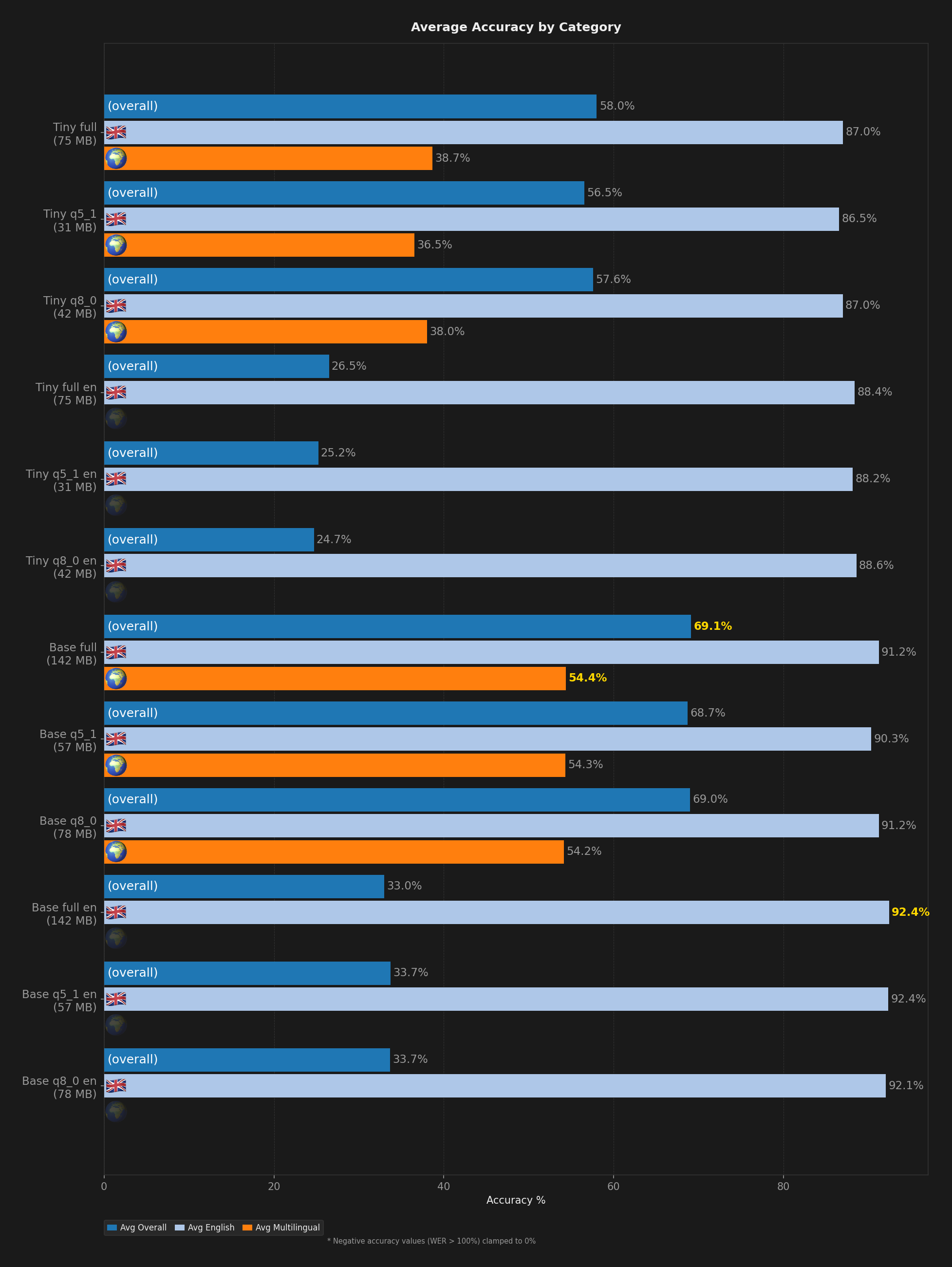 Figure 2: Average accuracy by category, English vs multilingual.
Figure 2: Average accuracy by category, English vs multilingual.
Multilingual accuracy: where Tiny and Base fall apart
| Model | Spanish | Danish | Hungarian | Avg. multilingual |
|---|---|---|---|---|
| tiny | 85.0% | 14.2% | 16.9% | 38.7% |
| tiny-q5_1 | 83.5% | 14.4% | 11.7% | 36.5% |
| tiny-q8_0 | 85.0% | 11.2% | 17.9% | 38.0% |
| base | 88.4% | 39.5% | 35.3% | 54.4% |
| base-q5_1 | 88.9% | 37.6% | 36.4% | 54.3% |
| base-q8_0 | 88.6% | 38.4% | 35.5% | 54.2% |
| Small (reference) | 94.1% | 64.3% | 59.4% | 72.6% |
The .en models are not in this table. They are English-only by design. When we ran them on Spanish, Danish, and Hungarian anyway, they produced word error rates above 96%. More errors than actual words in the audio.
Spanish is the one language where Base holds up. It manages 88.4-88.9%, which is reasonable. But Danish and Hungarian expose the model size. Tiny hits 14.2% on Danish and 16.9% on Hungarian. That is not usable transcription.
Base does better at 39.5% Danish and 35.3% Hungarian, but still far behind Small (64.3% and 59.4%). And Small itself was not great on those languages compared to Whisper Large, which scored 87.1% and 85.5% in our previous benchmark.
Memory and speed
| Model family | RAM range |
|---|---|
| Tiny | 150 - 227 MB |
| Base | 216 - 336 MB |
| Small (reference) | 476 MB |
Quantized variants deliver real memory savings. Base-q5_1 runs at 217 MB, less than half of Small's 476 MB. Tiny-q5_1 sits at 153 MB.
If you are on a machine with limited RAM, these numbers matter. Base-q5_1 gives you 90.8% English accuracy at 217 MB. That is a reasonable trade if you only dictate in English and want to keep memory use low.
Speed was nearly identical across all models in this triage. Every variant processed audio well under real-time on the M4 Max. At this model size, inference speed is not the differentiator. Figure 3 confirms that all variants cluster around the same processing time.
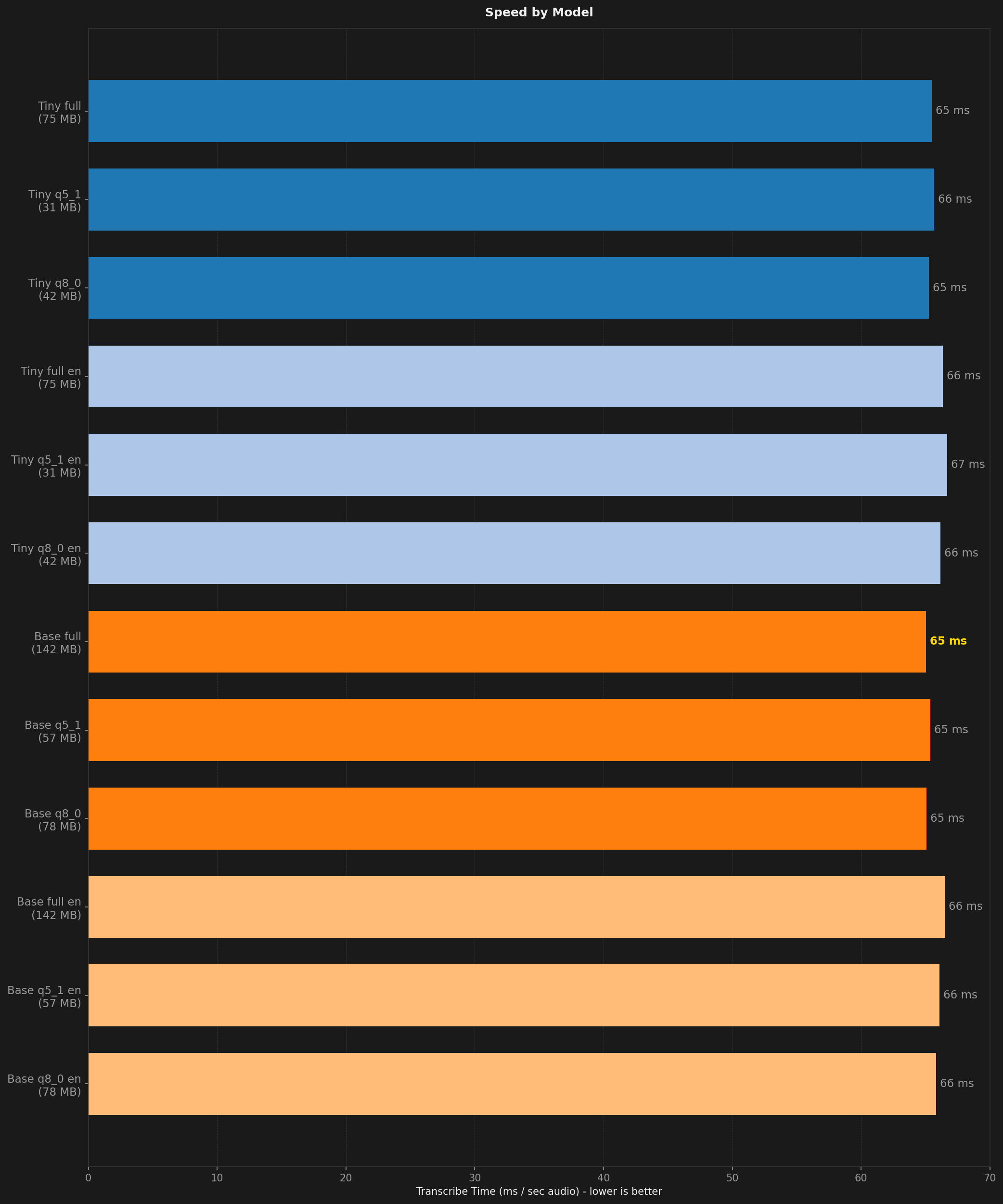 Figure 3: Speed comparison, milliseconds per second of audio.
Figure 3: Speed comparison, milliseconds per second of audio.
What we are testing next
This triage was designed to answer one question: which of these smaller models deserve a full benchmark?
Tiny is out. The accuracy gap is too wide across every condition. Even its best English variant sits nearly 6 points behind Small. For multilingual use, it is not functional.
Base.en is worth further testing on English. At 92.5% average English accuracy and 216-333 MB of RAM, it is within striking distance of Small. On noisy audio it actually beat Small at less than half the memory. For users who only dictate in English and want a lightweight model, Base.en could be a real option.
Base (multilingual) is not fully ruled out either. Spanish accuracy sits at nearly 89%, and the overall average stays above 50%. Danish and Hungarian are weak, but we want to confirm those results on a larger sample before making a final call.
We are working toward a comprehensive benchmark across all models so you can make a more informed decision about which model fits your workflow. This triage helps us focus that effort where it counts.
The full triage data is on the benchmarks page. For how the larger models performed, read the full benchmark post.